Hi all,
As part of my preparation for my main GSoC proposal, I’ve been exploring the pgRouting codebase and experimenting with various algorithms to get familiar with the project. During this process, I identified two issues that I believe could improve usability and clarity for users and contributors.
I’d like to ask if it’s okay to proceed with these changes, and if there are any specific guidelines I should follow.
1. King Ordering Documentation Inconsistency
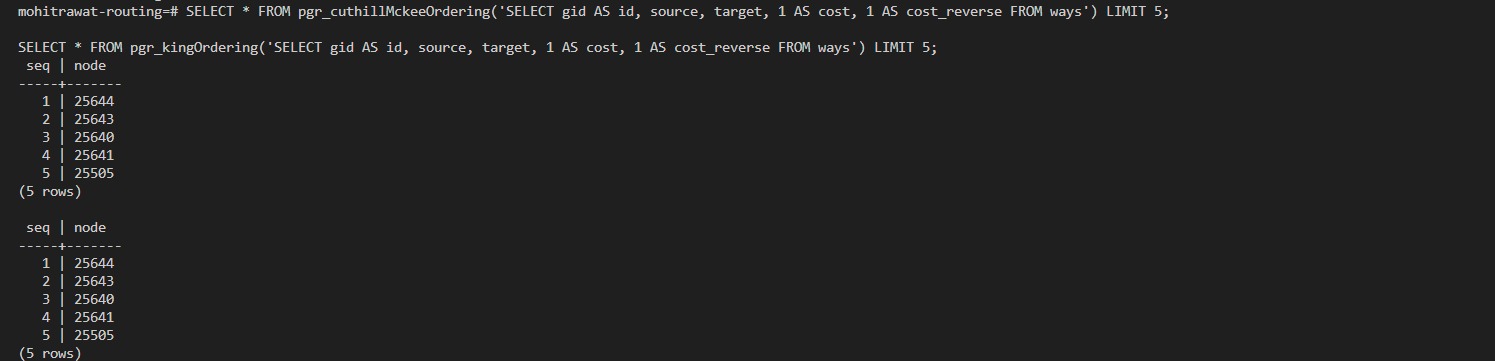
While testing the ordering algorithms, I ran both pgr_cuthillMckeeOrdering and pgr_kingOrdering on the same OSM-derived graph. Both functions returned identical node orders, which matches the “reverse” order as described in the Cuthill-McKee documentation. However, the King Ordering documentation doesn’t mention that it returns the reverse order, which could confuse users.


Suggestion: Update pgr_kingOrdering.rst to clarify that it returns the reverse King ordering of an undirected graph, consistent with the Cuthill-McKee documentation.
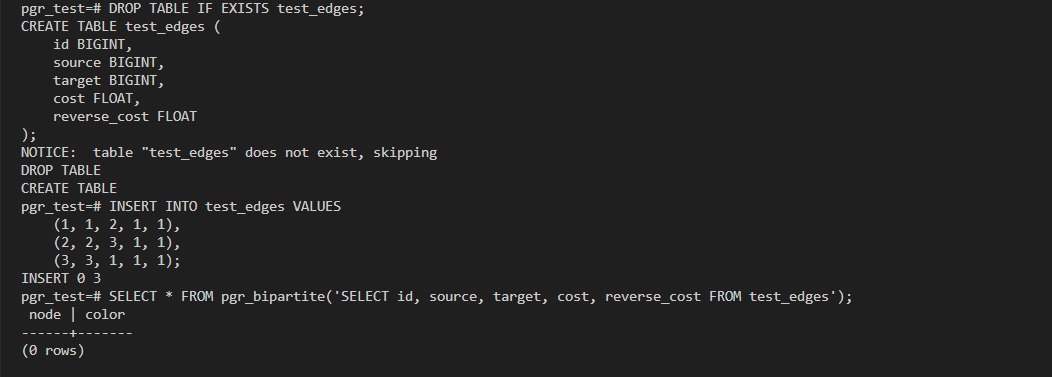
- Odd Cycle Detection in pgr_bipartite
Currently, pgr_bipartite only returns an empty set when a graph is not
bipartite, with no information about why. For large graphs, this makes
debugging difficult. Boost provides find_odd_cycle()
( Boost Graph Library: find_odd_cycle ),
which identifies the actual odd cycle breaking bipartiteness, but this
isn’t currently exposed in pgRouting.
Suggestion: Add a function (e.g., pgr_findOddCycle) that returns the odd cycle when a graph is not bipartite. This would help users debug and fix their data more efficiently, especially for large graphs.
If these suggestions make sense, I’m happy to implement them. Please let me know if there are specific contribution guidelines or review processes I should follow.
Best regards,
Mohit Rawat